AWS costs every programmer should know
The title for this blog post is a direct reference to Latency Numbers Every Programmer Should Know. There are several versions of those numbers available now, and I could not find the original author with certainty. Some people attribute the original numbers to Jeff Dean.
When working on a project that will reach a certain scale, you need to balance several concerns. What assumptions am I making and how do I confirm them? How can I get to market quickly? Will my design support the expected scale?
One of the issues associated with scale, is the cost of your infrastructure. Cloud providers allow you to provisions thousands of CPUs and store terabytes of data at the snap of a finger. But that comes at a cost, and what is negligible for a few thousand users might become a burning hole in your budget when you reach millions of users.
In this article, I’m going to list reference numbers I find useful to keep in mind when considering an architecture. Those numbers are not meant for accurate budget estimation. They’re here to help you decide if your design makes sense or is beyond what you could ever afford. So consider the orders of magnitude and relative values rather than the absolute values.
Also consider that your company may get discounts from AWS, and those can make a massive difference.
Compute
What’s the cost of a CPU these days? I used the wonderful ec2instances.info interface to extract the median price of a vCPU.
You can get the source data out of their Github repo. I copied it and processed it using a python script that you can find on Github. All prices are for the eu-west-1 region.
| Median monthly cost | |
|---|---|
| 1 modern vCPU (4 AWS ECUs) | 58 $/month |
| With 1 year convertible reservation (all up front) | 43 $/month |
| With 3 years convertible reservation (all up front) | 30 $/month |
| With spot pricing (estimated) | 30 $/month |
I estimated spot pricing based on anecdotal data I got from various sources. As the prices vary within a day and I could not find a reliable data source for it.
AWS represents the computing power of its machines in Elastic Compute Units, and 4 ECUs represent more or less the power of a modern CPU. So the prices above are for one CPU or core, not one instance.
Here’s the price of 1 ECU in $ per hour across all instance types I looked at:
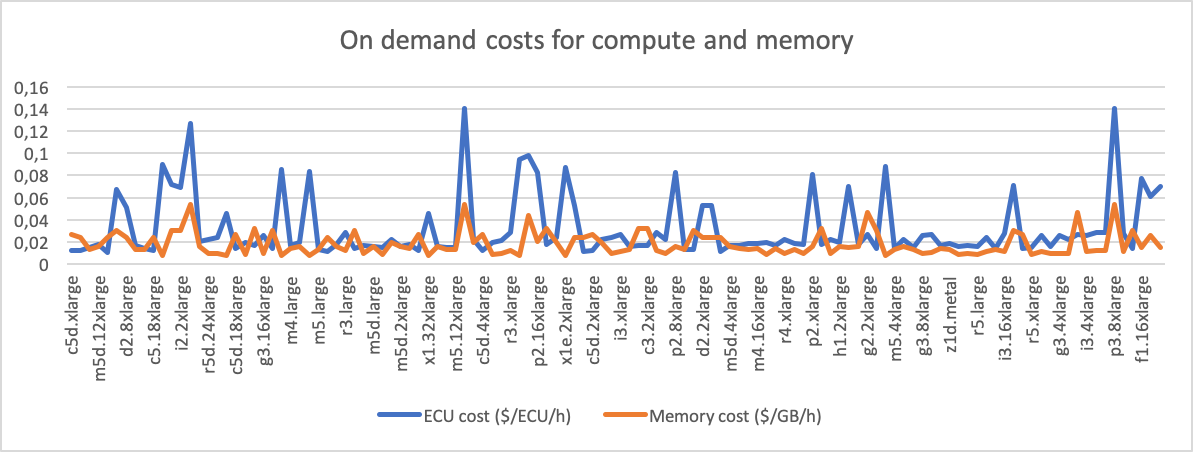
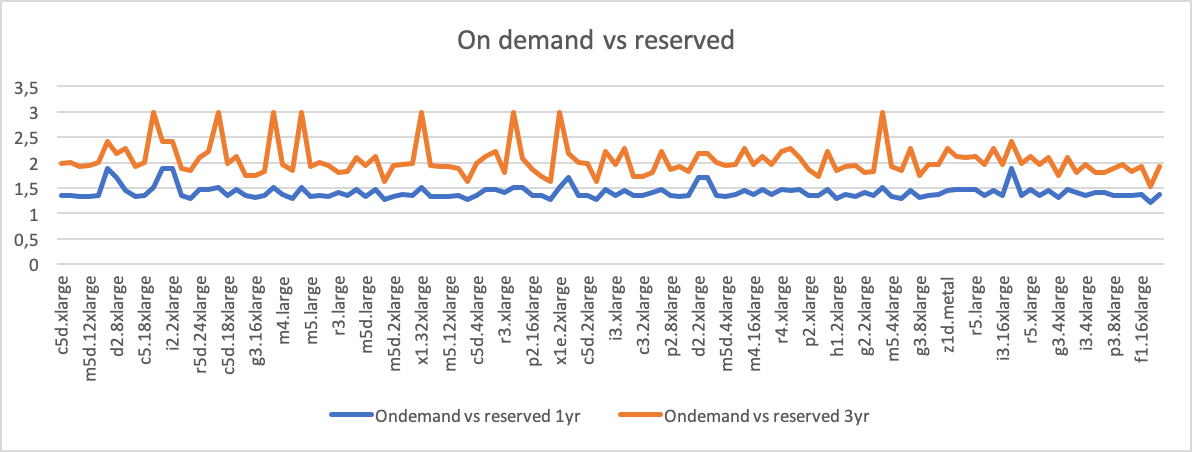
And here’s how on-demand compares with 1 year and 3 year reservations (both convertible, upfront payments):
Storage
So you want low latency, high throughput and are planning to store everything in Redis? Then on top of those CPU costs, you’ll need to pay for RAM.
I used the same approach to extract the median price of 1GB of RAM on EC2. Elasticache is more or less twice as expensive for on-demand but prices drop quite quickly when looking at reserved instances.
| Median monthly cost | |
|---|---|
| 1 GB RAM | 10 $/month |
| 1 GB RAM 1 year convertible reservation (all up front) | 8 $/month |
| 1 GB RAM 3 years convertible reservation (all up front) | 5 $/month |
| SSD | 0.11 $/month |
| Hard Disk | 0.05 $/month |
| S3 | 0.02 $/month |
| S3 Glacier | 0.004 $/month |
While this is the pure storage cost, you also need to look at the usage patterns for your data. How much CPU will you need to run that in-memory database 24/7?
Same for S3: how much will you pay in writing/reading requests? I’ve seen workloads where the storage cost on S3 was negligible but the cost of writing a lot of objects in S3 made the team write their own filesystem on top of S3.
Bandwidth
A few comments on HackerNews pointed out that I left the bandwidth costs out. Indeed if you are serving data to end users, or need cross-region replication, you need to look into those costs as well.
| Type of data transfer | Cost of transferring 1GB |
|---|---|
| EU/US region to any other region | 0.02 $/GB |
| APAC region to any other region | 0.09 $/GB |
| EU/US region to Internet | 0.05 $/GB |
| APAC region to Internet | 0.08 $/GB |
| Between two AZs in the same region | 0.01 $/GB |
| Inside the same AZ | Free |
16 Comments
These are archived comments from a previous comment system.
Forgot how expensive aws actually is...
Don't forget S3 Glacier Deep Archive $0.001/mo
AWS is not a cost benefit or a scalability benefit. It is an architecture benefit for those who don't want to have to maintain, pay and do it themselves. Thats IT! Period. The best benefit they offer is as backup and emergency deployment for.
Yes!
And the benefit is greatest to those with sporadic bursts of demand. Netflix, for instance, spins up thousands of servers on Friday and Saturday evening. By midnight, the servers are going away. They buy only a few hours.
If you're going to keep a machine running all of the time, it can get expensive for what you buy.
exactly. An architectural benefit... like I said.
Nice, Can you include AWS Serverless options like using AWS lambda/API Gateway. I think it would be much cheaper than looking at full blown EC2 instances
Are you kidding ?
Outside free tier AWS Lambda cost 6x the price of EC2.
thats the question. How is AWS lamdba 6x the price of EC2, if you are not running some continuous long running job, AWS lambda always beats the price of EC2. See here. Many times, the long running jobs especially those that are polling-heavy or memory intensive can be redesigned to be event driven and fit comfortably within AWS lambda. Am aware of the additional costs tied to AWS API gateway but either way, nothing compared to these EC2 costs
6x the price. Lambda do not always beat the price of EC2 especially if you are outside free tier.
They are uber interesting for small workloads and/or extra bursty workload.
If you can live with autoscaling pools of EC2 to adjust load it is cheaper.
https://pagertree.com/2018/...
I've recently felt the pain of the NAT Gateways costs! Yes, they're managed by AWS in comparison to NAT Instances, but that thing is $0.045 per HOUR + $0.045 per GB transferred - that's easily $50 per month PER NAT. Obviously we want HA, so there'll be multiple of these sucking our money out.
These NAT GW costs can easily be avoided by using TGW and PrivateLink (or VPC) Endpoints (which redirect/restrict NAT traffic and use the AWS internal network instead for AWS internal services).
This is not to say that they couldn't reduce the prices and make them more accessible for devs.
Didn't knew this! Thanks for the tip!
You should have mentioned "Each vCPU is a thread of a physical CPU core". Which means, when you buy an m5.large with 2 vCPUs, you get only one physical core and one logical core. That makes vCPU even more expensive.
Care to elaborate? How would the resulting thing resemble anything like a filesystem? And how did a custom FS solve the problem?
I personally do not know what they did but since you pay for GET's and PUT's as well, one could, for example, ZIP up a thousand files and store that ZIP on S3 with only one PUT. I would image a custom file system might do some similar by batching several object into a pseudo container and storing it with one PUT.
Actually there are two main storage areas of AWS: the object based S3 and the block based EBS. EBS is very expensive compared to S3. My AWS usage is limited to Alexa development and runs about $1.15/month. However, approximate $1 of that cost is an 8GB EC2 AMI image I have in EBS. CloudWatch is also another storage medium and it too can get expensive if you do not purge your logs (I keep mine between one and three days depending on the function I am dealing with).